

Did you know that even the most advanced Large Language Models (LLMs) have limitations when it comes to grasping context or generating highly specialized responses? Welcome to the world of AutoGen Applications, where we delve into an innovative solution: Retrieval Augmented Generation (RAG).
This technology not only amplifies the capabilities of LLMs but also introduces a new horizon in conversational AI.
In this article, we’ll unpack the components, mechanics, and customizations of RAG in AutoGen, offering you a roadmap to its practical applications and future potential.
1 The Concept of Retrieval-Augmentation
What is Retrieval Augmented Generation?
Retrieval Augmented Generation, or RAG, is a breakthrough technique in Natural Language Processing (NLP) that expands the horizons of conversational agents, particularly Large Language Models (LLMs). By dynamically retrieving contextually relevant information from a vast array of data sources, such as documents, images, tables, graphs, etc., this method enhances the quality and diversity of generated text in various NLP tasks.

Some examples of these tasks are question-answering, summarization, dialogue generation, and more. The objective is to make AI systems not just a tool but a more effective collaborator that can produce text that is not only coherent and fluent, but also informative, factual, and creative.
How Retrieval-Augmentation Can Mitigate the Limitations of LLMs
LLMs, despite their incredible scale and complexity, often fall short when nuanced or highly contextual responses are needed. They sometimes provide generic or overly broad answers that may not be helpful in specific scenarios. Retrieval-augmentation addresses this gap by integrating external sources of information, allowing LLMs to offer more targeted and contextually appropriate responses. In essence, it acts like a co-pilot, supplying the LLM with the necessary data to enhance its performance.
2 Importance in the Context of LLMs
How LLMs Can Be Limited in Their Scope and Understanding
LLMs are, by nature, limited by the data they’ve been trained on and the algorithms that power them. While they are excellent at processing language, they often lack deep comprehension or the ability to source external information dynamically. Their latent space, although rich, is finite, limiting their applicability in more specialized or nuanced tasks.
The Role of Retrieval-Augmentation in Enhancing LLMs’ Capabilities
Retrieval-augmentation serves as a critical add-on to existing LLM frameworks. By pulling in real-time data and supplementary information, it empowers LLMs to go beyond their built-in limitations. Whether it’s generating code or responding to intricate queries, retrieval-augmentation provides the needed “intellectual boost,” making LLMs more versatile, responsive, and effective in a wide range of applications.
3 Components of RAG in AutoGen

Let’s dive deeper into the mechanics of Retrieval-Augmented Generation within the AutoGen framework. To start, it’s essential to recognize that the architecture is primarily composed of two core agents: RetrieveUserProxyAgent and RetrieveAssistantAgent. In this section, we’ll focus on the former and its multifaceted role in the RAG architecture.
RetrieveUserProxyAgent
Responsibilities
- Specifies Document Collection Path: One of the first steps involves setting up the path for the document collection. This is where the agent will look for information to retrieve.
- Downloads and Segments Documents: After specifying the path, the agent is responsible for downloading the relevant documents. It then segments these documents into manageable chunks, making it easier to sift through the data.
- Computes Embeddings: Once the documents are segmented, the agent computes embeddings for each of these chunks. Embeddings are vectors that represent the content, and they are crucial for enabling quick and accurate retrieval.
- Stores Them in a Vector Database: Finally, these computed embeddings are stored in a vector database. This allows for efficient similarity matching when a user query comes in during a chat.
Mechanism of Operation
How It Initializes
The RetrieveUserProxyAgent starts by initializing its settings, which includes specifying the document collection path and configuring the database where the embeddings will be stored. Initialization often involves loading predefined configurations or default settings.
Its Role During a Chat Session
During a live chat session, the RetrieveUserProxyAgent springs into action when a query is posed. It uses the stored embeddings to perform a similarity search across the document chunks. Once it identifies relevant pieces of information, it forwards them to the RetrieveAssistantAgent for the next steps, which often involve generating a more contextually accurate and nuanced response.
Understanding the responsibilities and operational mechanisms of the RetrieveUserProxyAgent gives us foundational insights into the AutoGen RAG architecture. This agent serves as the backbone for contextual data retrieval, which is vital for generating relevant and accurate responses.
RetrieveAssistantAgent
Now that we have a good grasp of the RetrieveUserProxyAgent’s role in the AutoGen RAG system, it’s time to shine the spotlight on its partner in action: the RetrieveAssistantAgent. This agent takes the retrieved context and crafts it into the insightful and nuanced responses that RAG is renowned for. Let’s delve into its responsibilities and operating mechanics.
Responsibilities
- Generates Code or Text Based on Context: At its core, the RetrieveAssistantAgent is responsible for creating meaningful output—be it code or text—based on the context provided. This is the essence of its role in making the RAG system more effective.
- Interacts with RetrieveUserProxyAgent: It’s not a lone wolf. The RetrieveAssistantAgent closely collaborates with the RetrieveUserProxyAgent. It receives document chunks and other contextual information from the latter, using this data to craft more accurate and contextually relevant responses.
Mechanism of Operation
How It Utilizes Document Chunks Sent by RetrieveUserProxyAgent
When the RetrieveUserProxyAgent sends over document chunks, the RetrieveAssistantAgent gets to work. It parses the received data and uses its embeddings to understand the contextual relevance. This information is then integrated into the response generation process, allowing for much more accurate and context-aware answers.
What Happens When the Output Is Unsatisfactory
In cases where the generated output doesn’t meet the expected criteria, the RetrieveAssistantAgent has a built-in feedback mechanism. It can send a prompt saying “Update Context” to the RetrieveUserProxyAgent. This serves as a signal to revisit the document chunks and possibly fetch more relevant information for a better, more accurate response.
In summary, the RetrieveAssistantAgent is the creative brain behind the operation, while the RetrieveUserProxyAgent serves as the resourceful researcher. Together, they create a powerful duo that elevates the capabilities of Large Language Models in the AutoGen framework. Their seamless interaction and dynamic roles ensure that you get the most relevant and contextually appropriate responses, whether you’re coding or simply asking a question.
In our next section, we’ll take a look at how these agents communicate and interact during a live chat, creating a fluid and intelligent conversational flow.
4 Chat Flow Between Agents

Understanding the individual responsibilities and operations of RetrieveUserProxyAgent and RetrieveAssistantAgent in the AutoGen RAG system is crucial. But the magic truly happens when these agents communicate and collaborate during an active chat session. In this section, we’ll explore the sequence of their interactions and the underlying mechanics that govern the chat flow.
Sequence of Interactions
- User Query Initiation: The process starts when a user initiates a query. This query is first picked up by the RetrieveUserProxyAgent.
- Document Retrieval: RetrieveUserProxyAgent uses the pre-computed embeddings to find document chunks with high similarity to the user’s query. It retrieves these documents from its database.
- Passing Context to RetrieveAssistantAgent: The retrieved document chunks are then sent to the RetrieveAssistantAgent, along with the user’s query.
- Response Generation: RetrieveAssistantAgent, upon receiving the document chunks and the query, generates a context-appropriate response.
- User Feedback and Loop Continuation or Termination: The response is sent back to the user. If it’s satisfactory, the chat ends. If not, a feedback loop is initiated to refine the response.
Document Retrieval Based on Embedding Similarity
RetrieveUserProxyAgent uses the stored embeddings to perform a similarity-based search for relevant documents. This is done through techniques like cosine similarity or other vector space models that compare the query’s embeddings with the stored document chunk embeddings.
Generation of Code or Text Responses
RetrieveAssistantAgent crafts a response based on the received context. The generated response could be a code snippet or textual information that directly addresses the user’s query.
Feedback Loop
How “Update Context” Works
If the generated response is unsatisfactory, RetrieveAssistantAgent sends an “Update Context” signal to RetrieveUserProxyAgent. This prompt serves as an indicator for the latter to re-evaluate the document chunks and possibly fetch additional or alternative information.
Execution of Code and Feedback System
In scenarios where code is generated as the response, RetrieveUserProxyAgent takes on the responsibility of executing it. The output of this execution is then sent back as feedback, either confirming the code’s effectiveness or indicating a need for adjustments.
In summary, the chat flow between RetrieveUserProxyAgent and RetrieveAssistantAgent is a well-coordinated dance. Each agent plays its role impeccably, harmoniously contributing to the efficient and effective operation of the AutoGen Retrieval-Augmented Generation system. In our following sections, we’ll delve into the practical aspects of employing these agents, starting with the basics of installation and usage.
5 Basic Usage of RAG Agents

So you’re excited about the potential of Retrieval-Augmented Generation (RAG) in AutoGen and want to get your hands dirty. Great! In this section, we’ll go over how to set up and utilize these sophisticated agents to tackle a variety of tasks. From installation to asking your first question, we’ve got you covered.
Installation
Required Dependencies and How to Install Them
Before diving into the world of RAG agents, you’ll need to install some dependencies. The AutoGen package has made this process seamless. You can install all the required dependencies with the following command:
pip install "pyautogen[retrievechat]"Initialization and Configuration
How to Import Agents
Importing agents is a straightforward process. You can import the RetrieveAssistantAgent and RetrieveUserProxyAgent classes using the following Python code snippet:
from autogen.agentchat.contrib.retrieve_assistant_agent import RetrieveAssistantAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgentInitial Settings and Configurations
After importing the agents, you can create instances of them. For instance, to create a RetrieveAssistantAgent named “assistant” and a RetrieveUserProxyAgent named “ragproxyagent,” you can use:
assistant = RetrieveAssistantAgent(
name="assistant",
system_message="You are a helpful assistant.",
llm_config=llm_config,
)
ragproxyagent = RetrieveUserProxyAgent(
name="ragproxyagent",
retrieve_config={
"task": "qa",
"docs_path": "https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
},
)
Example Code Snippets
The following example code snippet shows how to initialize a chat and ask a question:
assistant.reset()
ragproxyagent.initiate_chat(assistant, problem="What is autogen?")Initiating Chats
How to Reset Agents
Before you start a new chat session, you might want to reset the agents to their initial states. You can use the .reset() method on the assistant like so:
assistant.reset()Process of Asking Questions and Receiving Responses
After resetting the assistant, you can initiate a chat and ask a question using the initiate_chat method:
ragproxyagent.initiate_chat(assistant, problem="What is autogen?")This kicks off the interaction between RetrieveAssistantAgent and RetrieveUserProxyAgent, culminating in the generation of a response to your query.
There you have it—a quick guide on how to install, configure, and use the AutoGen RAG agents. Up next, we’ll dive into the customizability options for these agents, allowing you to fine-tune your RAG experience.
6 Customizing RAG Agents
The power of AutoGen’s RAG system lies not just in its advanced capabilities, but also in its flexibility. Here we’ll explore how you can tailor the RetrieveUserProxyAgent and RetrieveAssistantAgent to better fit your specific needs.
RetrieveUserProxyAgent Customization
Different Options for Customization
-
Embedding Functions: These are the algorithms that convert text into a format that can be compared for similarity. You’re not stuck with the default; there are a variety of other options you can use, including OpenAI and HuggingFace models.
-
Text Split Functions: These algorithms determine how to divide a large document into manageable chunks. This is crucial for storage and rapid retrieval. You can either use the default splitter or choose one that suits your specific text data.
-
Vector Databases: This is where the text data, after being transformed by the embedding function, is stored for quick retrieval. AutoGen uses
chromadbby default, but you have the freedom to replace it with a database of your choice.
Examples
-
Customizing for OpenAI: If you prefer OpenAI’s algorithms for text embedding, there’s a way to switch to it. All you need to do is specify this preference when setting up your RetrieveUserProxyAgent.
-
Customizing for HuggingFace: Similarly, if you’re a fan of HuggingFace models, you can configure the RetrieveUserProxyAgent to use them instead.
RetrieveAssistantAgent Customization
Available Options for Customization
While RetrieveUserProxyAgent offers various ways to modify its behavior, RetrieveAssistantAgent is a bit more straightforward. You can customize it to some extent by altering the underlying settings of the large language model it uses.
- LLM Configuration: Here, you’re essentially fine-tuning how the large language model (LLM) that powers the RetrieveAssistantAgent behaves. This could affect how it understands and generates text based on the retrieved information.
With this level of customization, you can make AutoGen’s RAG agents work just the way you want, offering a tailored solution for a wide range of natural language processing tasks.
7 Advanced Usage of RAG Autogen Agents
One of the most exciting features of AutoGen’s RAG system is its adaptability for different scenarios. Not only can these agents be used in two-agent setups, but they can also be integrated into multi-agent environments like group chats. Below, we’ll walk through how to make the most out of RAG agents in such advanced settings.
Integration with Other Agents
Basic Understanding
To grasp the concept, let’s consider a group chat scenario involving different roles:
- A “Boss” who asks questions and assigns tasks.
- A “Senior Python Engineer” who works on technical tasks.
- A “Product Manager” who oversees the project’s overall progress.
- A “Code Reviewer” who ensures code quality.
Now imagine you want to introduce a specialized agent, the “Boss Assistant,” who has a unique capability for content retrieval to solve complex questions or tasks. This is where AutoGen’s RAG system comes in handy.
How It Works in Group Chat Scenarios
In a group chat, initialization is key:
-
Initialization with RetrieveUserProxyAgent: Usually, you’d initiate a group chat with this specialized content retrieval agent (the “Boss Assistant” in our example).
-
Initialization with Other Agents: In certain instances, you might want to start the chat with another agent like the “Boss.” In this case, you’ll need to call the RetrieveUserProxyAgent (“Boss Assistant”) within the function you use for interaction.
Function Registration
You can extend the functionality of each agent by registering specific functions. In our example, we register a retrieve_content function for all agents. This function enables any agent to tap into the “Boss Assistant’s” special content retrieval powers when needed.
Handling Requests
The “Boss” can initiate a chat asking for something like, “How to use Spark for parallel training?” The “Boss Assistant” can then retrieve relevant content to address this query, which the “Senior Python Engineer” can use to generate sample code, and so on.
8 Build a Chat application With Autogen RAG
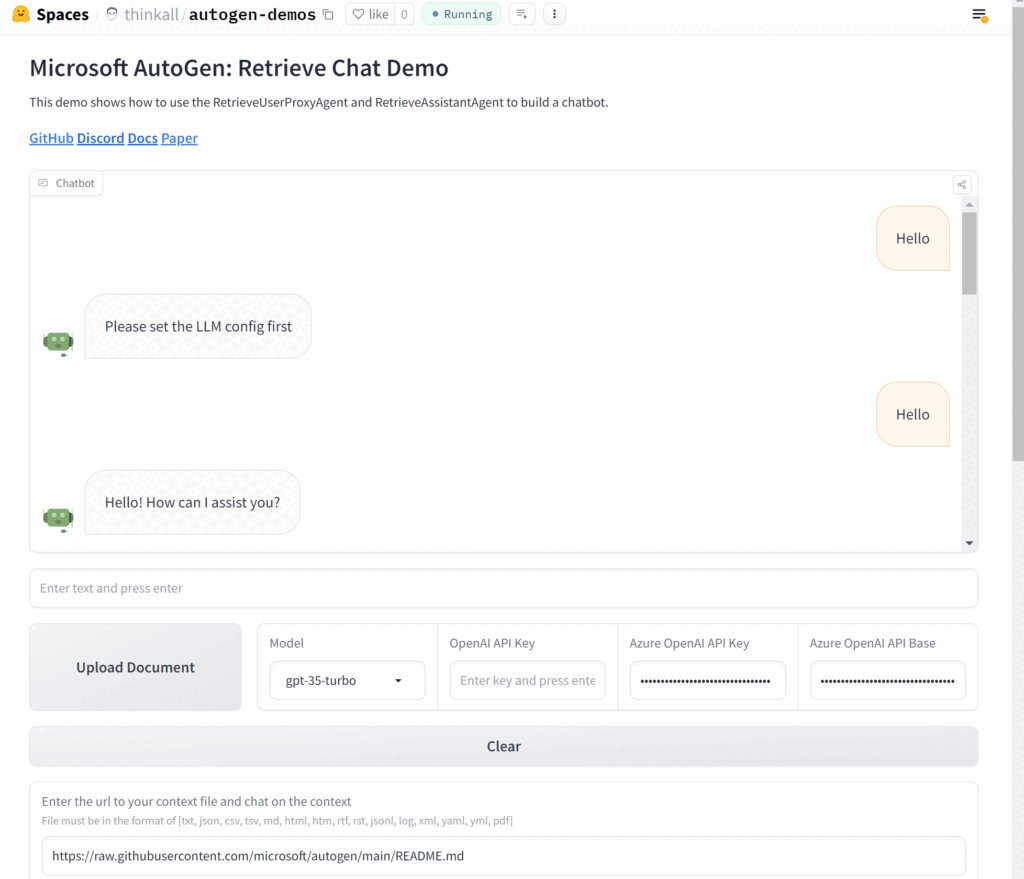
Try It Out!
The entire application and its source code are graciously hosted on HuggingFace. If you’re keen on experiencing this state-of-the-art RAG Chatbot in action, click here to try it out on HuggingFace.
9 Conclusion
In the landscape of conversational AI and Natural Language Processing, the AutoGen framework introduces Retrieval Augmented Generation (RAG) as a significant advancement. It tackles the limitations inherent to Large Language Models (LLMs) by dynamically pulling in real-time, contextually relevant data. This enables more nuanced and specialized responses during interactive sessions.
Read More :
CrewAI : How To Build AI Agent Teams
Embedchain AI : Best Open Source RAG Framework
AutoGen Studio UI 2.0 : Step By Step Installation Guide
How AutoGen Integrates with GPTs
What Are LLM Agents ? An Overview of Their Capabilities





{kind=link}
Discussion about this post